编程产出代码,代码是一种沟通工具。将代码当作一种沟通工具是非常重要的,因为现在所有项目基本上都要靠协作才能完成。即使你现在单枪匹马地工作,也肯定要与未来的自己进行交流!代码清晰易懂特别重要,这样其他人(包括未来的你)才能理解你为什么要使用这种方式进行分析。因此,提高编程能力的同时也要提高沟通能力,随着时间的推移,你不仅会希望代码更易于编写,还会希望它更容易为他人所理解。
写代码和写文章在很多方面是相似的。我们发现二者特别重要的一个共同之处是,要想让文章和代码更加清晰易懂,重写是关键。
对自己的想法第一次表达往往不是特别清除,因此需要多次重写。解决一个数据分析难题后,我们通常应该再审视一下代码,思考一下它是否真正实现了我们的要求。
当产生新想法时,如果花一点时间重写代码,就可以节省以后重构代码所需的时间。
- 第13章将深入介绍管道操作,即 %>%,你将学习更多关于管道操作的工作原理和代替方式,以及不适合使用管道的情形。
- 复制粘贴确实功能强大,但这种操作不应该超过两次。代码中的重复内容是非常危险的,因为这样很容易导致错误和不一致。第14章会介绍如何编写函数,这是重用代码的一种方式,它可以让你提取出重复代码,然后轻松地进行重用。
- 当开始编写功能更强大地函数时,你需要深刻理解R的数据结构,对应15章内容。必须掌握4种常用的原子向量,以及以此为基础构建的3种重要S3类,并理解列表和数据框背后的奥秘。
- 函数可以提出重复代码,但你经常需要对不同的输入重复相同的操作。你需要可以多次执行相同操作的迭代工具,这些工具包括 for 循环和函数式编程,这就是第16章将介绍的内容。
向量
准备工作
本章的重点在于介绍 R 基础包中的数据结构,因此无需加载任何R包。但是,为了避免 R 基础包中的一些不一致现象,我们会使用 purrr 包中的少量函数。
library(tidyverse)Warning message:
"package 'tidyverse' was built under R version 4.0.5"
-- [1mAttaching packages[22m ------------------------------------------------------------------------------- tidyverse 1.3.1 --
[32mv[39m [34mggplot2[39m 3.3.5 [32mv[39m [34mpurrr [39m 0.3.4
[32mv[39m [34mtibble [39m 3.1.2 [32mv[39m [34mdplyr [39m 1.0.7
[32mv[39m [34mtidyr [39m 1.1.3 [32mv[39m [34mstringr[39m 1.4.0
[32mv[39m [34mreadr [39m 2.1.0 [32mv[39m [34mforcats[39m 0.5.1
Warning message:
"package 'tibble' was built under R version 4.0.5"
Warning message:
"package 'tidyr' was built under R version 4.0.4"
Warning message:
"package 'readr' was built under R version 4.0.5"
Warning message:
"package 'dplyr' was built under R version 4.0.5"
Warning message:
"package 'forcats' was built under R version 4.0.3"
-- [1mConflicts[22m ---------------------------------------------------------------------------------- tidyverse_conflicts() --
[31mx[39m [34mdplyr[39m::[32mfilter()[39m masks [34mstats[39m::filter()
[31mx[39m [34mdplyr[39m::[32mlag()[39m masks [34mstats[39m::lag()
向量基础
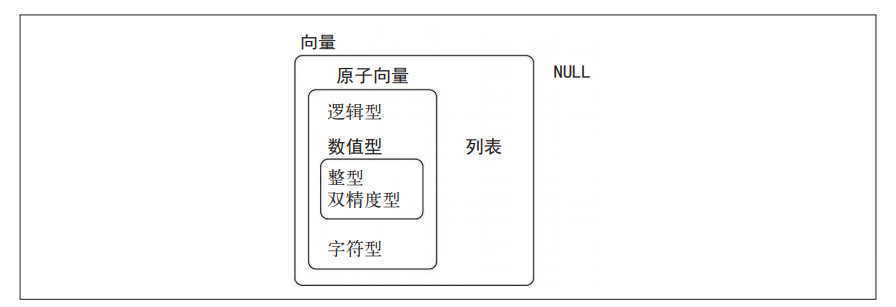
向量的类型主要两种:
- 原子向量,其共有6种类型:逻辑型、整型、双精度型、字符型、复数型和原始型。整数型 和 双精度型 统称为数值型向量。
- 列表,有时又称为递归向量,因为列表中也可以包含其他列表。
二者主要区别在于,原子向量中的各个值都是同种类型的,而列表中的各个值可以是不同类型的。 NULL是一个与向量相关的对象,用于表示空向量(与表示向量中的一个值为空的NA不同),通常指长度为0的向量。
每个向量都有两个关键属性。
- 类型。你可以使用
typeof()函数来确定向量的类型:
typeof(letters)‘character’
- 长度。你可以使用
length()函数来确定向量的长度:
x <- list("a","b",1:10)
length(x)3
还可以向向量中任意添加额外的元数据,这些元数据称为特性。特性可以用来创建创建向量,以执行一些新的操作。比较重要的拓展向量有4种类型。
- 基于整型向量构建的因子。
- 基于数值型向量构建的日期和日期时间。
- 基于列表构建的数据框和 tibble 。
本章将由浅入深地介绍这些重要向量。首先是原子向量、然后是列表,最后是拓展向量。
重要的原子向量
逻辑型
TRUE FALSE NA数值型
R中默认数值是双精度型的。如果想要创建整型数值,可以在数字后面加一个L:
typeof(1)‘double’
typeof(1L)‘integer’
1.5L1.5
双精度型是近似值。双精度型表示的是浮点数,不能由固定数量的内存精确表示。这意味着你应该将所有双精度数当成近似值。
在处理浮点数时,这种现象非常普遍:多数计算都包含一些近似误差。在比较浮点数时,不能使用 ==,而应该使用
dplyr::near(),后者可以容忍一些数据误差。整型数据有一个特殊值 NA,而双精度型数据则有4个特殊值:NA、NAN、Inf和 -Inf。其他3个特殊值都可以由除法产生:
c(-1, 0, 1) / 0- -Inf
- NaN
- Inf
不要使用 == 来检查这些特殊值,而应该使用辅助函数 is.finite()、is.infinite() 和 is.nan()。
字符型
R 使用的是全局字符串池。这意味着每个唯一的字符串在内存中只保存一次,每次对这个字符串的使用都指向这段内存,这样可以减少复制字符串所需的内存空间。
x <- "This is a reasonably long string."
pryr::object_size(x)
y <- rep(x, 1000)
pryr::object_size(y)152 B
8,144 B
y 所占的内存不是 x 的 1000倍,因为 y 中的每个元素都只是指向一个字符串的指针。
缺失值
注意,每种类型的原子向量都有自己的缺失值:
NA # 逻辑型
NA_integer_ # 整型
NA_real_ # 双精度型
NA_character_ # 字符型<NA>
<NA>
<NA>
NA
一般不需要考虑类型问题,可以一直使用NA,R会通过隐含的强制类型转换规则将其转换为正确的类型。
使用原子向量
强制转换
- 显式强制转换:调用 as.logical()、as.integer()、as.double() 或 as.character() 这样的函数进行转换
- 隐式强制转换:
在数值型摘要函数中使用逻辑向量。这种情况下,TRUE 转换为1,FALSE 转换为0.这意味着对逻辑向量求和的结果就是其中真值的个数,逻辑向量的均值就是其中真值的比例。
当试图使用c()函数来创建包含多种类型元素的向量时,清楚如何进行类型转换也是非常重要的。这时总会统一转换为最复杂的元素类型:
typeof(c(TRUE,1L))‘integer’
typeof(c(1L,1.5))‘double’
typeof(c(1,5, "a"))‘character’
原子向量中不能包含不同类型的元素,因为类型是整个向量的一种属性,不是其中单个元素的属性。如何需要在同一向量中包含混合类型的元素,那么就需要使用列表。
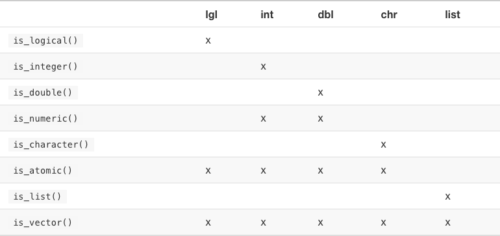
检验函数
有时我们需要根据向量的类型进行不同的操作。检验向量类型的一种方法是使用 typeof() 函数,另一种方法是使用检验函数来返回 TRUE 或 FALSE。R 基础包中提供了很多这样的函数,如is.vector() 和 is.atomic(),但它们经常返回出人意料的结果。更可靠的方法是使用 purrr 包提供的 is_* 函数族,以下表格总结了它们的使用方式。
标量与循环规则
R 可以隐式地对向量类型进行强制转换,同样地,也可以对向量长度进行强制转换。这种转换称为向量循环,因为R会将较短的向量重复到与较长的向量相同的长度。混合使用向量和“标量”时,向量循环是最有用的。
我们在标量上加了引号,因为R中没有真正的标量,只有长度为1的向量。正因为没有标量,所以R的多数内置函数都是向量化的,即可以在数值的一个向量上进行操作。这就是以下代码可以运行的原因。
sample(10) + 100
runif(10) > 0.5- 106
- 103
- 102
- 104
- 109
- 107
- 110
- 105
- 108
- 101
- FALSE
- TRUE
- FALSE
- FALSE
- TRUE
- TRUE
- FALSE
- FALSE
- FALSE
- FALSE
在R中,基本的数学运算是使用向量来进行的,这意味着在进行简单数据计算时,根本不需要执行显式迭代。
两个长度相同的向量或者一个向量和一个“标量”相加,结果是显而易见的。
如果两个长度不同的向量相加,R就会拓展较短的向量,使其与较长的向量一样长,这个过程就称作向量循环。如果较长的向量不是较短向量长度的整数倍,会出现warning。
1:10 + 1:2- 2
- 4
- 4
- 6
- 6
- 8
- 8
- 10
- 10
- 12
1:10 + 1:3Warning message in 1:10 + 1:3:
"长的对象长度不是短的对象长度的整倍数"
- 2
- 4
- 6
- 5
- 7
- 9
- 8
- 10
- 12
- 11
向量命名
所有类型的向量都是可以命名的。
c(x=1, y=2, z=4)- x
- 1
- y
- 2
- z
- 4
也可以在向量创建完成后,使用 purrr::set_names() 函数来命名:
set_names(1:3, c("a","b","c"))- a
- 1
- b
- 2
- c
- 3
向量命名对于向量取子集特别重要。
向量取子集
[ 就是取子集函数,调用形式是x[a]。你可以使用以下4种形式来完成向量取子集操作。
- 使用仅包含整数的数值向量。整数要么全部为正数,要么全部为负数,或者为0。
使用正整数取子集时,可以保持相应位置的元素:
x <- c("one","two","three","four","five")
x[c(3,2,5)]- 'three'
- 'two'
- 'five'
位置可以重复
使用负整数取子集时,会丢弃相应位置的元素:
x[c(-1,-3,-5)]- 'two'
- 'four'
正数与负数混合使用则会引发一个错误:
- 使用逻辑向量取子集。这种方式可以提取出TRUE值对应的所有元素,一般与比较函数结合起来效果更佳:
x <- c(10, 3, NA, 5, 8, 1, NA)
x[!is.na(x)]- 10
- 3
- 5
- 8
- 1
- 如果是命名向量,那么可以使用字符向量来取子集:
x <- c(abc = 1, def = 2, xyz = 3)
x[c("xyz", "def")]- xyz
- 3
- def
- 2
- 取子集的最简方式就是什么都不写:
x[], 这样就会返回x中的全部元素。
这种方式对于向量取子集没有什么用处,但对于矩阵(或其他高维数据结构)取子集则非常重要。
因为这样可以取出所有的行或所有的列,只要将行或列保持为空即可。例如,如果 x 是二维的,那么x[1,]可以选取出第一行和所有列,x[,-1]则可以选取出所有行和除第一列外的所有列。
[有一个重要的变体[[。[[从来都是只提取单个元素,并丢弃名称。
递归向量(列表)
列表是建立在原子向量基础上的一种复杂形式,因为列表中可以包含其他列表。这种性质使得列表特别适合表示层次结构或树形结构。
x <- list(1,2,3)
x- 1
- 2
- 3
列表可视化
为了解释清楚更复杂的列表操作函数,列表的可视化大有裨益。
列表取子集
列表取子集有三种方式,接下来我们通过列表a来说明:
a <- list(a = 1:3, b = "a string", c = pi, d = list(-1,-5))- 使用
[提取子列表。这种方式的结果总是一个列表:
str(a[1])List of 1
$ a: int [1:3] 1 2 3
- 使用
[[从列表中提取单个元素。这种方式会从列表中删除一个层次等级:
str(a[[1]]) int [1:3] 1 2 3
$是提取列表命名元素的简单方式,其作用与[[相同,只是不需要使用括号:
a$a- 1
- 2
- 3
对于列表来说,[和[[之间的区别非常重要。[[会使列表降低一个层级,而[则会返回一个新的、更小的列表。

特性
任何向量都可以通过其特性来附加任意元数据。可以将特性看作可以附加在任何对象上的一个向量命名列表。可以使用 attr() 函数来读取和设置单个特性值,也可以使用attributes()函数同时查看所有特性值:
x <- 1:10
attr(x, "greeting")NULL
attr(x, "greeting") <- "Hi!"
attr(x, "farewell") <- "Bye!"
attributes(x)- $greeting
- 'Hi!'
- $farewell
- 'Bye!'
3种特别重要的特性可以用来实现R中的基础功能。
- 名称
- 维度
- 类:用于实现面向对象的S3系统。可以控制泛型函数的运行方式。
泛型函数是R中实现面向对象编程的关键,因为它允许函数根据不同类型的输入而进行不同的操作。
拓展向量
原子向量和列表是最基础的向量,使用它们可以构建出另外一些重要的向量类型,比如因子和日期。这些构建出来的向量为拓展向量,因为他们具有附加特性,其中包括类。因为拓展向量中带有类,所以它们的行为就与基础的原子向量不同。
因子
因子是设计用来表示分类数据的,只能在固定集合中取值。因子是在整型向量的基础上构建的,添加了水平特性:
x <- factor(c("ab","cd","ab"), levels = c("ab","cd","ef"))
typeof(x)‘integer’
attributes(x)- $levels
-
- 'ab'
- 'cd'
- 'ef'
- $class
- 'factor'
日期和日期时间
tibble
使用 purrr 实现迭代
减少重复代码主要有3个好处
- 更容易看清代码的意图。吸引我们目光的东西是那些不同的部分,而不是那些保持不变的部分。
- 更容易对需求变化做出反应。当要修改代码时,只需要在一处进行修改即可
- 更容易减少bug,因为每行代码都被多次使用
函数是减少重复代码的一种工具,其减少重复代码的方法是,先识别出代码中的重复模式,然后将其提取出来,成为更容易修改和重用的独立部分。
减少重复代码的另一种工具是迭代,它的作用在于可以对多个输入执行同一种处理,比如对多个列或多个数据集进行同样的操作。
本章将介绍两种重要的迭代方式:命令式编程和函数式编程。
library(tidyverse)Warning message:
"package 'tidyverse' was built under R version 4.0.5"
-- [1mAttaching packages[22m ------------------------------------------------------------------------------- tidyverse 1.3.1 --
[32mv[39m [34mggplot2[39m 3.3.5 [32mv[39m [34mpurrr [39m 0.3.4
[32mv[39m [34mtibble [39m 3.1.2 [32mv[39m [34mdplyr [39m 1.0.7
[32mv[39m [34mtidyr [39m 1.1.3 [32mv[39m [34mstringr[39m 1.4.0
[32mv[39m [34mreadr [39m 2.1.0 [32mv[39m [34mforcats[39m 0.5.1
Warning message:
"package 'tibble' was built under R version 4.0.5"
Warning message:
"package 'tidyr' was built under R version 4.0.4"
Warning message:
"package 'readr' was built under R version 4.0.5"
Warning message:
"package 'dplyr' was built under R version 4.0.5"
Warning message:
"package 'forcats' was built under R version 4.0.3"
-- [1mConflicts[22m ---------------------------------------------------------------------------------- tidyverse_conflicts() --
[31mx[39m [34mdplyr[39m::[32mfilter()[39m masks [34mstats[39m::filter()
[31mx[39m [34mdplyr[39m::[32mlag()[39m masks [34mstats[39m::lag()
for 循环
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)我们想要计算出每列的中位数。
output <- vector("double", ncol(df)) # 1. 输出
for (i in seq_along(df)){ # 2. 序列
output[[i]] <- median(df[[i]]) # 3. 循环体
}
output- 0.0958849547446843
- -0.306585623094582
- 0.0416632570547124
- -0.0808040981927321
输出: output <- vector(“double”, length(x))
在开始循环前,你必须为输出结果分配足够的空间。这对循环效率非常重要,如果在每次迭代中都使用 c() 来保存循环的结果,那么 for 循环的速度就会特别慢
序列: i in seq_along(df)
这部分确定了使用哪些值来进行循环:每一轮 for 循环都会赋予 i 一个来自于 seq_along(df) 的不同值。
seq_along() 函数的作用,它与 1: length(l) 的作用基本相同,但最重要的区别是更加安全。
不过,使用 vector 应该注意一点的是,命名只能是数字。如上的例子,结果不再是以 “a”, “b”, “c”, “d” 命名,最后可通过 names(output) <- c()的形式进行重命名,或者数据量不大的时候,用 list() 替代 vector() 的使用。
for 循环的变体
修改现有变量
有时我们希望使用 for 循环来修改现有的对象。
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
rescale01 <- function(x){
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
df$a <- rescale01(df$a)
df$b <- rescale01(df$b)
df$c <- rescale01(df$c)
df$d <- rescale01(df$d)使用 for 循环解决这个问题
for (i in seq_along(df)){
df[[i]] <- rescale01(df[[i]])
}要记住使用的是 [[ 而不是 [。在所有 for 循环中,使用的都是[[。我们认为甚至在原子向量中最好也使用[[,因为它可以明确表示要处理的是单个元素
循环模式
对向量进行循环的基本方式有3种。
- 之前使用的 for (i in seq_along(xs))
- 使用元素进行循环: for (x in xs)
- 使用名称进行循环: for (nm in names(xs)). 可以使用
x[[nm]]来访问元素的值
如果想要创建命名的输出向量,一定要按照以下方式进行命名:
x = 5
results <- vector("list", length(x))
names(results) <- names(x)用数值索引进行循环是最常用的方式,因为给定位置后,就可以提取出元素的名称和值:
for (i in seq_along(x)){
name <- names(x)[[i]]
value <- x[[i]]
}未知的输出长度
有时你可能不知道输出的长度。你或许会想通过逐渐增加向量长度的方式来解决这个问题。
但这并不是一种非常高效的方式,因为R要在每次迭代中复制上一次迭代中的所有数据。从技术角度来看,你执行了一种“平方”操作。
更好的解决方式是将结果保存在一个列表中,循环结束后再组合成一个向量:
means <- 1:3out <- vector("list", length(means))
for (i in seq_along(means)){
n <- sample(100,1)
out[[i]] <- rnorm(n, means[[i]])
}
str(out)List of 3
$ : num [1:64] 1.386 2.401 0.535 1.508 -0.165 ...
$ : num [1:97] 1.73 1.55 1.71 1.34 2.88 ...
$ : num [1:50] 1.65 3.54 3.73 3.23 4 ...
str(unlist(out)) num [1:211] 1.386 2.401 0.535 1.508 -0.165 ...
这里使用 unlist() 函数将一个向量列表转换为单个向量。
其他情况下也可以使用这种编码模式:
- 一个很长的字符串。不要使用
paste()函数将每次迭代的结果与上一次连接起来,而应该将每次迭代的结果保存在字符向量中,然后再使用 paste(output, collapse="") - 一个很大的数据框。不要在每次迭代中以此使用
rbind()函数, 而应该将每次迭代结果保存在列表中,再使用dplyr::bind_rows(output)将结果组成数据框
只要遇到类似情况,就应该使用一个更复杂的对象来保存每次迭代的结果,最后一次性合并起来。
未知的序列长度
输入序列的长度未知,比如抛硬币时,直到掷出正面。这种不能通过 for 循环,而应用 while 循环。
while (condition){
# 循环体
}while 循环也比 for 循环更常用,所有 for 循环都可以用 while 循环实现,但反过来不一定。
while (i <= length(x)){
# 循环体
i = i+1
}for 循环与函数式编程
映射函数
先对向量进行循环,然后对其每个元素进行一番处理,最后保存结果。这种模式太普遍了,因此 purrr 包提供了一个函数来完成这种操作,每种类型的输出都有一个相应的函数:
- map() 用于输出列表
- map_lgl() 用于输出逻辑型向量
- map_int() 输出整型向量
- map_dbl() 双精度型向量
- map_chr() 字符型向量
每个函数都是用一个向量作为输入,并对向量的每个元素应用一个函数,然后返回和输入向量同样长度的一个新向量。向量的类型由映射函数的后缀决定。
可能有人会告诉你不要使用 for 循环,因为它们很慢,错!(for 已经很多年都不慢了)。使用 map() 函数的主要优势不是速度,而是简洁:它们可以让你的代码更容易编写,也更易读。
map(df, mean)- $a
- 0.576563294456781
- $b
- 0.686022544487736
- $c
- 0.530912642473943
- $d
- 0.423394367376984
map_dbl(df, mean)- a
- 0.576563294456781
- b
- 0.686022544487736
- c
- 0.530912642473943
- d
- 0.423394367376984
map_dbl(df, median)- a
- 0.591578766581408
- b
- 0.764083328457511
- c
- 0.600418254821894
- d
- 0.405819916629453
df %>% map_dbl(median)- a
- 0.591578766581408
- b
- 0.764083328457511
- c
- 0.600418254821894
- d
- 0.405819916629453
df %>% map_dbl(sd)- a
- 0.283172420608764
- b
- 0.295247328617479
- c
- 0.297714845287434
- d
- 0.339448515188844
map_* 和 col_summary() 具有以下几点区别
- 所有 purrr 都是用 C 实现的,速度很快
- 第二个参数,可以是一个公式、字符向量或整型向量
见下快捷方式 - map_*() 使用 … 向 .f 传递一些附加参数,供其在每次调用中使用:
- 映射函数可以保留名称
快捷方式
对于参数 .f, 你可以 使用几种快捷方式来减少输入量。假设你想对每个数据集中的每个分组都拟合一个线性模型。按照气缸值进行分类将 mtcars 数据集拆分成3个部分,并对每个部分拟合一个线性模型:
models <- mtcars %>%
split(.$cyl) %>%
map(function(df) lm(mpg ~ wt, data=df))
models$`4`
Call:
lm(formula = mpg ~ wt, data = df)
Coefficients:
(Intercept) wt
39.571 -5.647
$`6`
Call:
lm(formula = mpg ~ wt, data = df)
Coefficients:
(Intercept) wt
28.41 -2.78
$`8`
Call:
lm(formula = mpg ~ wt, data = df)
Coefficients:
(Intercept) wt
23.868 -2.192
因为 R 中创建匿名函数的语法比较繁琐,所以 purrr 提供了一种更方便快捷方式——单侧公式:
models <- mtcars %>%
split(.$cyl) %>%
map(~lm(mpg ~ wt, data = .))在以上示例中使用了 . 作为一个代词:它表示当前列表元素(与 for 循环中用 i 表示当前索引是一样的)。
当检查多个模型时,有时你会需要提取出像 R2 这样的摘要统计量。想要完成这个任务,需要先运行 summary() 函数,然后提取出结果中的 r.squared。我们可以使用匿名函数的快捷方式来完成这个操作:
models %>% map(summary) %>% map_dbl(~.$r.squared)- 4
- 0.50863259632314
- 6
- 0.464510150550548
- 8
- 0.422965536496111

