awk 语法
awk [-options] 'script' [var=value] file
# 或
awk [-options] -f scriptfile [var=value] file
# 或
cat file | awk [-options] 'script' [var=value]重点在 script 上,比较复杂却也相应的实用,内容较多时可写成文件形式;var=value一般涉及到引入外部变量
注意: awk 后面接的是单引号awk ''
awk 基本结构

BEGIN 模块
放置执行前的语句,BEGIN模式的经常性设置有
- FS(field separator,输入列分隔符)
- OFS(output FS)
- RS(record separator,输入行分隔符)
- ORS(output RS)
- OFMT (output format, 设置输出格式,用于 printf,如 “%.4f”)
都可以是正则表达式,写在双引号之间,例如BEGIN{FS="[\t| |a-z]";OFS="\t"}
也可以将变量初始化放在这里,如:BEGIN{n=0;sum=0};应该注意一点的是:这里的变量(n, sum)以及引入的外部变量(var),都不需要通过$ 引用
还可以做程序开始行为
awk 'BEGIN { print "Hello, world!" }'“办事”模块
使用运算符和/或匹配模式进行处理
END 模块
这里面放的是处理完所有的行后要执行的语句。如结束语,或者输出最后的计数结果
awk 'BEGIN { print "Hello, world!" }END{ print "Good bye!" }'awk 支持的正则表达式元字符
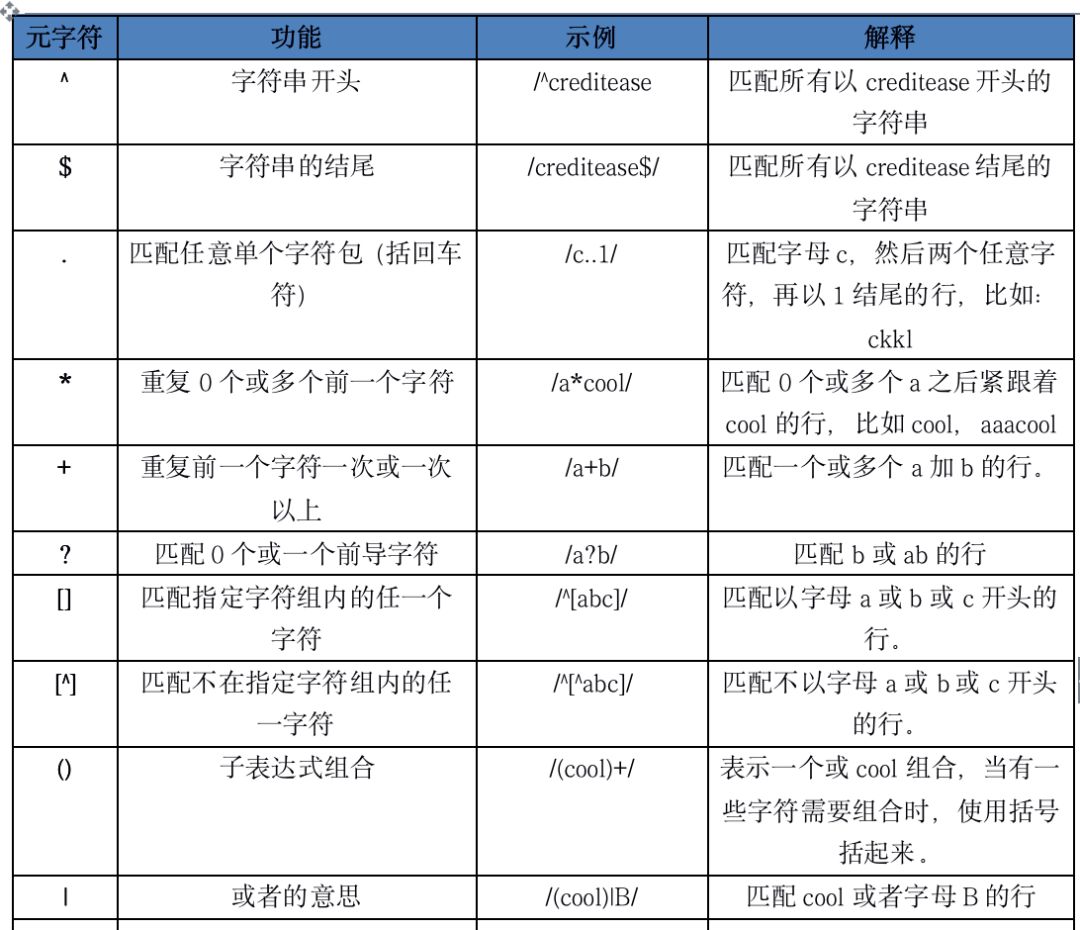
awk 运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || && | 或,与 |
| ~ !~ | 匹配,不匹配 |
| < <= > >= != == | 关系运算符 |
| + - * / % | 加减乘除余 |
| ^ *** | 求幂 |
| ++ -- | 加加,渐渐 |
awk '$1==2 && $2=="Are" {print $1+1,$3}' log.txt 筛选匹配字符的行
awk '$2 ~ /pattern/' log.txt
awk '$2 !~ /pattern/' log.txtawk 内置变量
| 变量名 | 属性 |
|---|---|
| $0 | 当前记录整行 |
| $1,$2,…. | 当前记录第 n 个field,由 FS 分隔 |
| NF | 列数,number of field |
| NR | 行数,number of row |
| IGNORECASE | 忽略大小写,设为0(FALSE),1(TRUE) |
| OFMT | 数字的输出格式(默认值是%.6g) |
更多见参考资料
awk 内置函数
split
awk 的内建函数 split 允许把一个字符串分隔未单词并存储在数组中。
格式:
split(string, array, field separator)
split(string, array) # 如果第三个参数没有提供,默认为 FS 值$ time="12:34:56"
$ echo $time | awk '{split($0,a,":");print a[1],a[2],a[3]}'
12 34 56substr
返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。
格式:
substr(s,p) # 返回字符串s中从p开始的后缀部分
substr(s,p,n) # 返回字符串s中从p开始长度为n的后缀部分$ echo "123" | awk '{print substr($0,1,1)}'
1length
$ echo $time | awk 'split($0,a,":"){print length(a[1])}'
2toupper/tolower
$ echo file | awk '{print toupper($1)}'
FILE
$ echo FILE | awk '{print tolower($1)}'
filegsub
gsub函数则使得在所有正则表达式被匹配的时候都发生替换。
格式:gsub(/匹配字符串/,目标字符串,域)
gsub(regular expression, subsitution string, target string) # 简称 gsub(r,s,t)。举例:把一个文件里面所有包含 abc 的行里面的 abc 替换成 def,然后输出第一列和第三列
$ awk '$0 ~ /abc/ {gsub("abc", "def", $0); print $1, $3}' abc.txt$ echo "a b c 2011-11-22 a-d" | awk 'gsub(/-/,"",$4)'
a b c 20111122 a-d而 '{print gsub(expression)}' 会打印替换的次数,如上例改写
$ echo "a b c 2011-11-22 a-d" | awk '{print gsub(/-/,"",$4)}'
2运算函数
| 函数 | 解释 |
|---|---|
| atan2(x,y) | y,x范围内的余切 |
| sin,cos | 正余弦 |
| exp(x) | 求幂 |
| int(x) | 取整 |
| log(x) | 自然对数 |
| rand() | 随机数 |
| sqrt(x) | 平方根 |
| srand(x) | x是rand()函数的种子 |
log()
以 e 为底,其他底数的对数,可以根据换底公式进行转换
如以 2 为底:log(x)/log(2) 即可
一些示例
计算文件大小
ls -l *.txt | awk '{sum+=$5} END {print sum}'脚本示例
假设有如下成绩表:
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62awk 脚本如下:
$ cat cal.awk
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}执行结果:
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00设置输出格式
awk 'BEGIN{OFS="\t";OFMT="%.6f"}{m1=($2+$3)/2;m2=($6+$7)/2;printf "%s\t%d\t%d\t%.4f\t%.4f\n",$1,m1,m2,$4,$9}' result.txt | less根据某列分割文件
cat raw.file | awk '{print > ("prefix" $1 "suffix")}'
